10 juli 2019

As projects grow in size and complexity, it can be easy to get lost in your own code base. Does this function return X, or Y. Can it return null? Does the doc block still match the function? Is this function even used anymore? We will use static analysis to answer these questions, and identify potential problems in our code. We will dive into what static analysis is, and a few of the tools that are available.
One of the best ways to check if your code is correct, is to test it. We use automated tests to check if we didn’t introduce regression. When dealing with legacy code, where a lot of the logic in intertwined, it may be difficult to start with writing tests. You will need to invest a lot of time to test even the smallest things. Static analysis can find a lot of errors in the code, without ever executing it. Static analysis won’t be able to replace your tests, but it can compliment them.
The idea is that we check our code for faults, without executing it, and without the need to write additional code to check it. A lot of work that it does is something that a compiler might do in a compiled language. For example, take a look at the following golang function:

If this function is anywhere in a program, it will not run, or even compile. Because the compiler notices that we have 2 faults in our program. The first one is that we compare a string to a boolean, which are different types and can never be the same. The second fault is that we may return a string instead of an int.
If we would write this function in PHP, we can still run our program. And until the moment we try to execute this function, nothing will go wrong. However, the moment we try to execute this and return a string, we will get a type error. Unless we have a test that checks that specific code path, we will not find out about it. Static analysis will find this error for us, without having a test that checks that specific path, and without even executing the code at all.
If we are working in an older code base, without return types, we can still infer type information from doc comments like @return int. If that information is also missing, a function may be checked to see what it can actually return. The more information a static analyser has about the intended use of a function, the more possible faults it can find.
We’ll take a look at some of the popular static analysis tools, and see what benefits they provide us with.
PHPStan
PHPStan is currently one of the most popular static analysis tools, with nearly 4 million composer downloads at the time of writing this post. It requires PHP 7.1 or higher to run, but it is capable of analysing code that runs on lower PHP versions.
PHPStan can be installed through composer, or you can use a phar if that is your preferred method of installation. Running it for the first time is surprisingly simple: the command vendor/bin/phpstan analyse app will analyse the app folder, and provide you with all the errors it finds.
PHPStan groups its rules in levels, each level building on top of the previous one. So level 0 are mostly issues your IDE would point out as well. Level 1 already adds a few more, up to level 7, or ‘max’, which is the highest level of rules. Here any error PHPStan can find will be pointed out to you.
Level 0 will find errors that will (most likely) crash when executed. For example, attempted access of private or protected properties. Or uses of self or static outside of classes. Most of these faults will probably be picked up by your IDE.
Level 1 is already a bit more strict, finding errors that will trigger warnings, like using undefined variables and constants.
Levels 2 and 3 come with type checks, that would not cause any errors when executed. For example a property that is annotated as being an integer, when in reality it is a string.
Level 4 helps with finding if statements that will always return true (or false), or loops over empty arrays.
Levels 5 through 7 offer even more strict checks, for example on union types, or possible null values.
For most projects, using level 4 is more than enough, and levels 5 or higher will provide little benefit for the time it takes. However, for a greenfield project, using level 7 is very viable. There is no need to fix a lot of old ‘errors’, so it takes less time to maintain that level.
In a configuration file levels and paths can be specified, so those don’t have to be present in the command line every time. It also allows you to specify a bootstrap file, and even ignore errors.
Ignoring specific errors is done through regex, which can lead to a few issues when incorrectly implemented. It allows users to create their own rules, through extensions, and has a few ‘official’ extensions, providing better support for certain frameworks and tools.
It also ran surprisingly fast. On a project with 217 files to analyse, it took roughly 4 seconds to run on level 0. When running it at the maximum level it took 6 seconds, due to more rules being checked.
Now let’s take a look at a bit of the output. I ran it in a project, and among a long list of errors were the following:
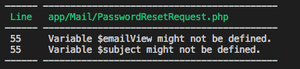
The following code was responsible for the error:
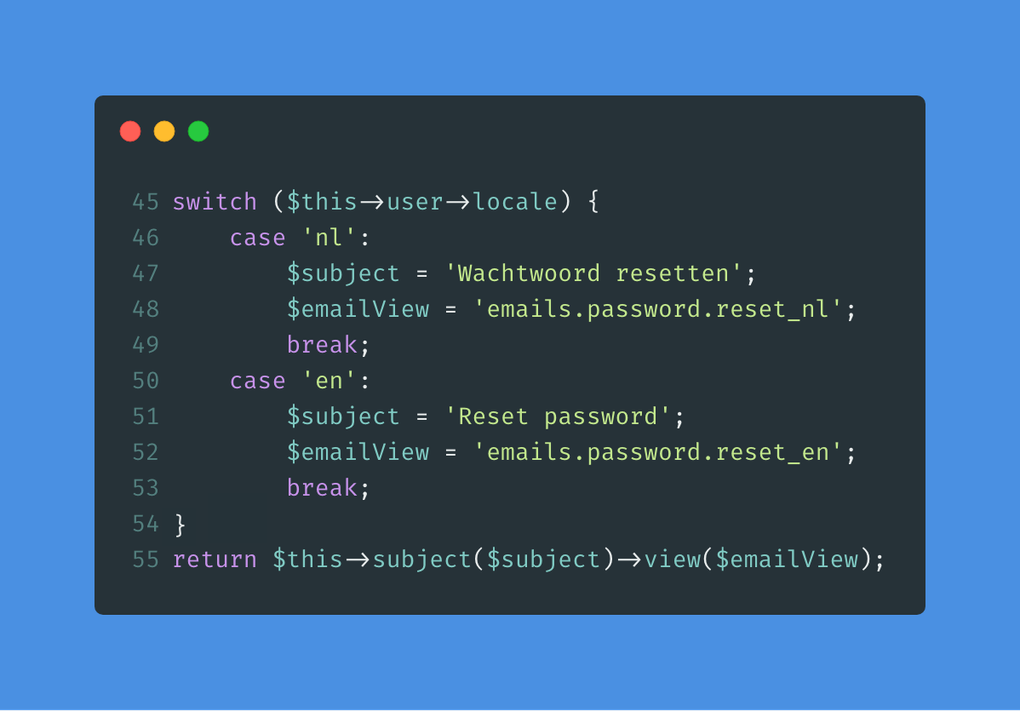
The code in question only has ‘nl’ and ‘en’ locale, so it shouldn’t be an issue. However, in case something goes wrong, or a locale is added, then we may possibly send an email without a subject or view. So if we make the default throw an error that tells us what is going on, or send the email in english, we can save us a lot of headaches in the future.
Psalm
Although not as popular as PHPStan, Psalm still has over 360 thousand composer downloads. It requires PHP 7.0 or higher to run, but can analyse older code as well. Just like PHPStan, Psalm can be installed both as a composer dependency, or as a phar.
Psalm uses an xml file to do its configuration, and also allows usage of doc blocks within the code to ignore specific errors. Before the first run you will have to run vendor/bin/psalm –init which will generate a configuration file, after that a simple vendor/bin/psalm will suffice.
Psalm allows you to configure each rule individually. Each rule has the option to define its error level. ‘info’ will give you the error, but not fail the command. Using ‘error’ will cause the program to exit with an error. The last option is ‘suppress’, which will allow you to suppress the error for certain files, or for the entire code base.
Allowing very specific configuration per directory is one of Psalms strong points. When you are dealing with an older legacy code base it allows you to specify better standards for the newer code, without forcing you to fix every issue the ‘old’ code has. Or it allows you to be stricter with critical code. It also allows you to create a baseline, which means you can allow all your ‘old’ code to have its errors, but be very strict about any new code that gets written.
One of the nice features of Psalm is its psalter command. This allows you to automatically fix the code. It is not possible to fix all issues, but it does add return types, or even remove dead(unused) code.
Running it on the previously mentioned code base took roughly 10 seconds. One of the errors it found was the following:
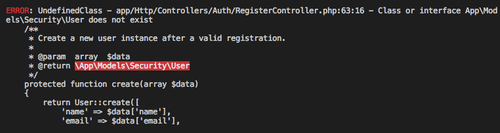
This was a surprising result, as the application does have users. There is the possibility to create users, and log in. We dug around a bit, and found that this was a class that was generated at the start of the project. However, a new class was created to handle these actions, and the ‘old’ generated class was never actually used. The generated models that this class references were removed, as our own logic was created. This class however was never deleted.
Thanks to psalm we discovered that we could safely delete this class, and never have to worry about it again.
Other tools
These are just two of the many static analysis tools available. There is Phan, which focuses on preventing false positives, rather than finding more errors. And Exakat, which provides a lot more functionality, like finding incompatibilities with certain PHP versions, or even finding if you are using suboptimal functions.
There are other tools like PHP_CodeSniffer and PHP CS Fixer, which aren’t static analysers, but linters/style checkers. Or a tool like PHPMD, which doesn’t focus on types, but checks for complex code. You could also consider this a static analysis tool, but I would say that mess detection is a genre on its own.
Day to day usage
Although static analysis tools don’t ‘suffer’ from the previously mentioned economy of tests, there is still a time investment to be made. In a brownfield project, you may find yourself spending a long time, just to fix all errors the tools point out, even if those wouldn’t actually break anything, like faulty doc comments. You may want to start on a lower ‘level’, and work your way up incrementally. For greenfields projects, its best to set up strict rules right from the start, and adhere to those. Some tools even have IDE plugins, which will give you the feedback, as you are writing the code.
In conclusion
Use static analysis. Whether its phpstan, exakat, psalm, or another tool, use one, or two, or all of them. There isn’t really a downside besides the initial time investment, to having these kinds of tools tell you all the things that are wrong in your code base. And they are configurable to ignore the errors you know, but just don’t care about. In a legacy project, I’d start with fixing the errors these tools find, before tests are being written.
If you like to know more about static analysis or you need help implementing it, just let us know!